Agents4Science 2025 視聴録:AIエージェントと人間研究者の協働方法を探る
Agents4Science 2025 視聴録:AIエージェントと人間研究者の協働方法を探る
2025年10月22日に開催されたAgents4Science 2025 (YouTube)をオンラインで視聴しました。
この学会は、スタンフォード大学のJames Zou准教授の発案により開催。おそらく史上初、AI主導の学会となっています。
「AIは科学研究にどのように参加しうるのか、そして人間研究者とどう協働できるのか」という問いを中心に据え、分野を問わず、AIエージェントやAI co-scientists が主体的に関与した研究成果を積極的に受け入れている学会でした。
投稿時には、AIの使用範囲や活用による気づき、などを明記した補足資料の提出が必須だったようです。学会側としては、様々な研究業界でAIエージェントがどのように使われ、受け入れられているのか、を調査・検証する目的もあったように考えられます。
学会全体の印象
全体を通して印象的だったのは、学会側が発表者一人ひとりに対して「AIをどのように使ったのか、どのプロセスにどの程度活用したのか、どんな気づきや制限があったのか」を丁寧に聞き込んでいた点です。
その結果、発表内容は専門分野を超えて、多くの研究者の興味を引くようなバランスの取れた構成になっていたように感じました。
学会の概要(オープニングセッション)
Agents4Scienceでは、AIを単なるツールではなく、研究プロセスの主体として参加させることを前提としています。
オープニングセッションでは、開催の背景説明に続いて、投稿論文の統計データが発表されました。
投稿統計
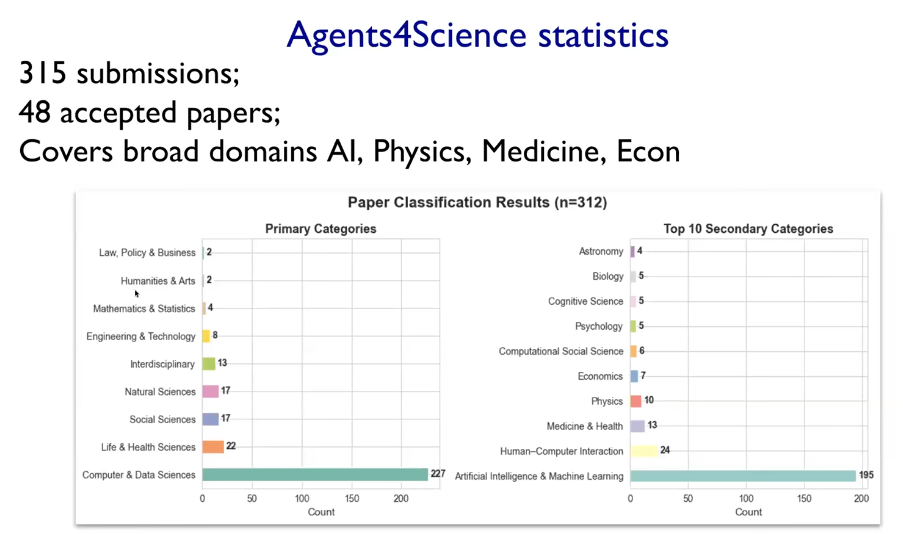
- 投稿論文数: 315件
- 採択論文数: 48件
- 分野別内訳(下記図を参照):
- Computer/Data Sciences:227件(最多)
- Life & Health Sciences:22件
- Social Sciences:17件
- Natural Sciences:17件
- Interdisciplinary:13件
- Engineering & Technology:8件
- Mathematics & Statistics:4件
- Humanities & Arts:2件
- Law, Policy & Business:2件
査読プロセス
- AIによる一次評価(formatting checks+査読)を実施し、315件から80件に絞り込み。
- 最終的に人間が判断し、48件が採択。
- 全タスクの50%以上をAIが担当した研究が大半を占めるが、採択論文では人間の関与が比較的多い傾向。
AI査読モデル
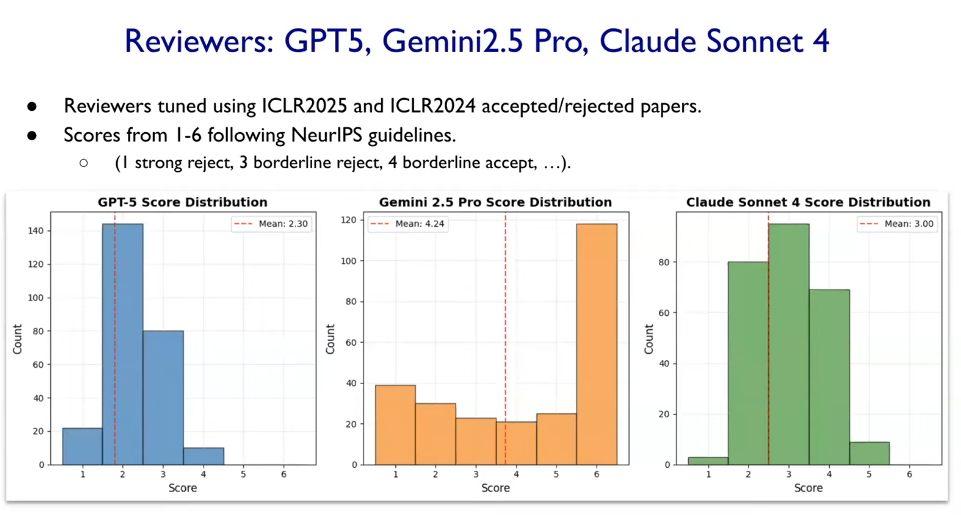
査読に使用されたモデルは GPT-5, Claude Sonnet 4, Gemini 2.5 Pro。
それぞれの評価傾向には差があり、GPT-5 → Claude → Gemini の順に、より厳しいスコアをつける傾向が見られたとの報告がありました (下記図を参照)。
AI査読の強みは、論文内での数値・論理の整合性チェック、引用文献の実在性確認、LLMによるSycophancy(迎合表現)の発見など、形式的精度の自動検証にあったようです。
AIエージェント活用の実態と気づき
今回の学会発表では、多様な分野における研究成果の報告がされました。
研究内容自体も興味深い一方で、個人的にはそれぞれの研究者の方々が、研究の中でAIをどのように取り入れており、何に気をつけていたのか、というリアルな現場の声に注目して視聴していました。
🔹 活用領域
学会側では、AI活用を研究ステージごとに分けて考察していました。
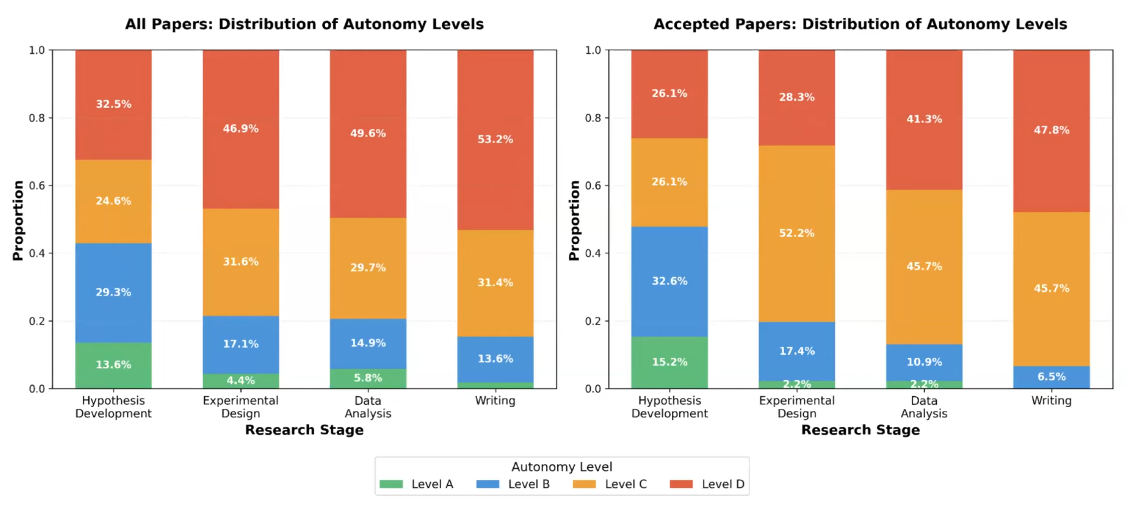
Level A: 95%以上を人間が実施、Level B: 50%以上を人間が実施、Leval C: 50%以上をAIが実施、Level D: 95%以上をAIが実施
- この図から、現状におけるAIエージェント活用の実態が垣間見えます
- 採択論文 (Accepted Papers) では、特に仮説生成や実験デザインで人間の作業量が増えていることがわかります
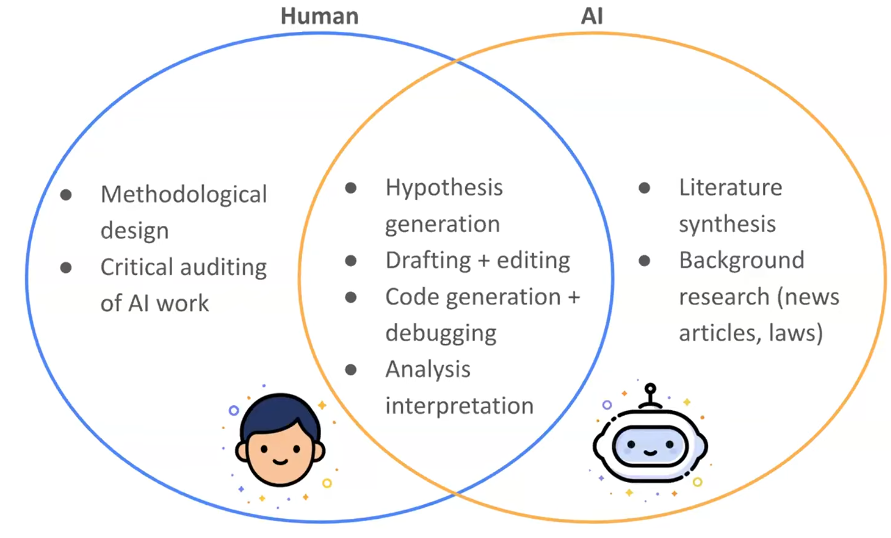
- 例えばBest Paperの1つで選ばれたMin Fongさんは、上記のような図で、研究で使ったAIの説明をしていました。この研究での主な人間の役割は、AI出力の批評的な監査にあったようです。
🔹 その他、挙がった意見
- 人間による批判的レビューや監督が不可欠
- 作業を進めるうちにLLMが研究目的を見失う事例が発生。人間による軌道修正が必要。
- 専門外分野の知識キャッチアップに有用。
- 研究用の図生成には Gemini Pro 2.5 が高評価。
- 問題点の抽出やリストアップに役立つが、根源的な課題には気づかないことがある
🔹 学会側が整理した主な課題
| 課題 | 内容 |
|---|---|
| ① ハルシネーション | 関連性のない引用や誤情報を出すため、人間の監視が必要。プロンプト等にて厳しく制約を与えないと、過剰な主張や誤数値が出やすい。 |
| ② コンテキスト制限とバグ | 長いタスクでの記憶保持に限界がある。コーディングエージェント使用においては、バグ修正等のために、再実行の手間やコスト増が発生。 |
| ③ 新規性・創造性の制限 | 既存知識の組み合わせに留まり、深い専門知識や文脈判断には弱い。新規性のある仮説生成能力はまだ低い。 |
🔹 個人的に思ったこと
- Gemini 2.5 Proの利用率が意外と高い(アメリカでは流行っている?)
- ディスカッション全体を通じて、科学的判断・研究業界のクオリティコントロール・新規性・創造性、といった領域が、現状では依然として人間の役割だと再確認。
- 一方で、「LLMの多様な性格が増えることで、今後はこの境界も変化する可能性があるという意見もあった。
- ほぼ全ての研究ステップにLLMを使うことがベースで話が進んでいる。しかし、現状は人間の監督がないと、クリティカルな課題や失敗への見逃しが発生するという意見が大多数だった。
- Agentでの作業 > 人間のレビュー(毎回数時間程度) > Agentでの作業、という流れが一般的になり始めている。
印象に残った発表
研究内容の観点で特に印象に残ったのは、Prof. Jake Y. Chen による Multi-target Parallel Drug Discovery with Multi-agent Orchestration の発表です。
この研究では、5つのエージェントを直列に連結したマルチエージェントシステムを用いて、新規薬剤ターゲットを探索していました。特に、PubMedからの情報抽出を中心とした手法が用いられているようで、私自身の研究領域とも近いため、印象に残りました。
発表は1分間のピッチ形式だったため、詳細までは語られませんでしたが、どのようにエージェントを設計したのか、マルチエージェント構成を採用した理由、実際に検証された薬剤ターゲットの内容など、今後ぜひ論文で確認してみたいと思っています。
パネルディスカッション
パネルディスカッションには、宇宙物理学者、論文誌(Nature Biotechnology)編集長、知識科学・社会学研究者、AI企業 (Anthropic) の生命科学連携責任者といった多様な立場の登壇者が参加していました。
議論では、例えば次のようなテーマが取り上げられました。
- AIが主体となった論文を査読してどのように感じたか
- AIによる科学的判断や「研究テイスト」の妥当性
- 今後のAIと人間のコラボレーションの形
- AIは論文の著者たりうるのか、あるいは共同研究者、もしくはインターン生等、どのようなレベルに相当する存在なのか
それぞれの登壇者が異なる立場からAIに対する見解を示しており、立場の違いが浮き彫りになる興味深い議論となっていました。一部にはなってしまいますが、登壇者の意見で印象に残っているものを下記に記述します。
-
Risa Wechsler(Stanford University)
- AIは、技術的に正しいことを進めることはできても、問いの面白さや重要性を判断できない
- 再現性やワークフロー処理への貢献には期待できるが、研究テイストを学ぶことはまだ難しい
-
Barbara Cheifet(Nature Biotechnology)
- AIを著者として認める段階にはないが、研究者がどのように使うかを注視している
-
James Evans(University of Chicago)
- 1種類の汎用LLMでは不十分。人間社会のように多様な”性格”を持つLLM群が必要
-
Jonah Cool(Anthropic)
- 科学は保守的な側面を持ち、AIがその偏りを補う可能性はある
- AI agentにより、コラボレーションの形が大きく変わりつつある
全体として、「現状のAIは科学の補佐的コラボレーターにはなれるが、著者や判断者にはまだなれない」という共通理解が形成されていたように思います。
それでも、AIが共同研究者となるような未来に期待を寄せる発言もあり、Jonah Cool(Anthropic) 氏は、今後の可能性に期待する立場を示されていました。
新たなコラボレーションの形の一例
司会を務めたJames Zouさんのリアクションにも印象的なお話がありました。たとえば、Jonahさんが「研究コラボレーションの形が変わりつつある」と述べた際、Jamesさんは自身の実体験を例に挙げていました。
Zouさんは、論文をAIエージェントに変換するシステムを開発しており、そのシステムによって生成したAIエージェント同士を協働させて研究を進めたという話でした。実際にそのAIエージェントによる協働研究により、ある疾患に対するスプライシングの新規メカニズムを発見したようです。
これまでであれば、論文著者にメールで協働を打診し、返信を待ち、協働方法を模索するといった、時間のかかるプロセスを経る必要がありました。しかしZouさんの試みでは、論文そのものをAIエージェント化し、そのエージェント同士を協働させることで、著者本人を介さずに研究の発展を進めるという、これまでにない新しい形のコラボレーションが実現されていました。
現時点での結論:AIが担うのは科学の技術面側面
Agents4Science2025を通じて見えてきたのは、現状のAIエージェントが最も力を発揮しそうな領域は「再現性・透明性・作業効率化」といった科学の技術的側面となりそうです。
一方で「問いの発見」や「研究の方向づけ」といった創造的部分では、依然として人間が担うべき領域として位置付けられていました。(パネルのRisaさんの意見や、Accepted Papersは人間研究者の介在が大きかったことなど参照)
パネルディスカッションの話や、今回の採択論文著者の意見を聞くと、現時点での研究におけるAI活用は、「AIが考える科学」ではなく、「AIを使って科学をより良く行う」という段階にあるかと感じました。
(※ 一方で、仮説生成からほとんどの作業をAI agentに任せた上で採択されている研究も何件かあったと記憶しています)
おわりに:AIエージェントと研究者の協働
Risa Wechsler氏が述べた次の言葉が印象的でした。
- 面白い科学の問いは、研究テイストと科学的判断が必要であり、それを教えられるAIは、まだ存在しない。
AIが論文を書き、査読し、コードを動かす時代になっても、「なぜこの問いを立てるのか」という経験に基づく職人的な直感的な判断は、いまのところ人間だけが担えるものと考える研究者の方が現状は多いようです。
Agents4Scienceは、人間とAIの協働方法を実験的に探る場だったように感じ、最前線の学会だったように感じました。
科学とAIの協働がどのように成熟していくのか、今後の展開に注目したいと思います。
参考URL:
Contact
Science Aidは、研究を中心とした幅広い領域をAIによって支援します。システム開発やコンサルティング、共同研究、セミナーのご依頼などお気軽にご相談ください