AIで研究はどう変わるのかーライフサイエンス分野から見る「AI for Science」
AIで研究はどう変わるのかーライフサイエンス分野から見る「AI for Science」
1. はじめに
2025年10月、文部科学省の第44回情報委員会において「AI for Scienceの実現に向けて」が議題として取り上げられました[1]。政府が描く将来像は3つの柱から構成されています:
- 「科学基盤モデル」の国産開発によるAI駆動型研究開発の強化
- 研究システムの自動・自律・遠隔化による研究データの創出・活用の高効率化
- 「AI for Science」を支える次世代情報基盤の構築
なぜ今、日本が科学研究の変革を急ぐのでしょうか。AIは科学研究のあり方そのものを変えうる技術であり、海外ではAIインフラの整備や研究投資が加速しています。一方で、第44回情報委員会の【資料1-5】AI for Scienceの推進に向けた基本的な考え方について[2]では「日本のAI利用やAI for Scienceの取組は国際潮流から大きく遅れている」と記載されています。日本がAI for Scienceを進めていくには、特にここ数年が勝負となります。
では、日本がどこから巻き返しを図るべきか。前述の【資料1-5】では、日本の強みを活かすべきであり、ライフサイエンス分野は強みの一つであると述べられています。
例えば、iPS細胞を活用したオルガノイド(幹細胞を培養して作成する臓器や組織を模した構造物)研究は、日本が世界をリードしてきた領域であり、最先端のデータを生み出す力があります。バイオイメージングやゲノムシーケンシングなど、日本が長年積み上げてきた計測技術により、良質なデータを取得できます。そして、これまで蓄積されてきた良質な実験データは、AIを活用する上で大きな強みとなる重要な資産です。
ただし、こうしたデータが研究室ごとに閉じてしまっていては十分に活用できません。そのため現在、研究データをコミュニティで共有し、相互利用できるようにするためのデータベースの統合・標準化が進められています。これにより、ライフサイエンス分野の強みをAIが最大限に引き出せる環境が整いつつあります。
2. ライフサイエンス分野におけるAI for Scienceのインパクト
ライフサイエンス分野の研究は、生命現象解明の複雑さが大きな障壁となっています。ゲノム、細胞、個体、次世代など複数の階層からなる生命システムの理解は容易ではありません。また、実験の多くが手作業で時間を要し、再現性に限界があります。しかし、AI活用による研究の高度化・効率化によって突破口を開く可能性があります。
現在の研究現場ではすでに、基盤モデルによる探索の加速・予測の精密化・新分子デザインの高速化が普及しつつあります。 今後はさらに、AIによる仮説生成支援、実験の自動化、解析の自動化・高速化が広く浸透し、研究サイクル全体がAI主導で高速に回る時代へ進むと考えられます。
将来的には、日本の研究力の再興、創薬イノベーションを通じた創薬力の向上、個別化医療・予防、バイオトランスフォーメーション(バイオテクノロジーによる、持続可能な経済社会)の実現が期待されています。
3. 研究活動を担うAI ― AIはどこまで”科学者”になれるのか
第44回情報委員会の【資料1-2】AI for Science / 概念と方向性[3]では、人間の研究活動を支援する道具としてのAIを「支援系AI4S」、研究活動を実行する主体としてのAIを「自律系AI4S」と定義しています。 これまでの科学研究におけるAI活用は、人間の研究活動を補助する「支援系AI4S」が中心でしたが、今後もその適用分野の拡大や性能の向上が進むと考えられます。一方で、現時点では限定的ではあるものの、研究活動そのものを担う「自律系AI4S」が今後発展し、科学研究の在り方に大きな変化をもたらす可能性があります。
本章では、自律的に研究プロセスを支援・実行するAIエージェントを4つ紹介します。それぞれ異なるアプローチと自律度を持ち、科学研究の異なる側面を自動化しています。
AI co-scientist(Google)
Googleが2025年に開発したAI co-scientistは、複数の専門エージェントが協働するマルチエージェントシステムです[4]。発表論文ではバイオメディカル分野で検証していますが、幅広い科学分野に応用可能な汎用性を持ちます。
研究者が自然言語で研究目標を与えると、6つの専門エージェントにより新しい研究仮説と提案が生成されます:
- Generation agent:初期仮説を生成
- Reflection agent:正確性・質・新規性から仮説を評価
- Ranking agent:仮説をトーナメント形式で比較しランキング
- Proximity agent:類似アイデアのクラスタリングや重複排除、仮説空間の効率的な探索を可能にする
- Evolution agent:トーナメントで上位にランクされた仮説を継続的に洗練
- Meta-review agent:レビュー結果を分析・統合し、他のエージェントを最適化して仮説生成の質を継続的に高める
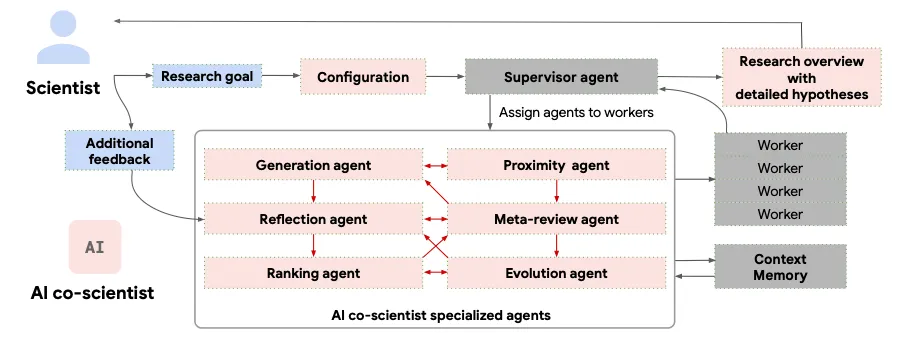
AI co-scientistの概要[4]
このシステムは”scientist-in-the-loop”設計を採用しており、完全自動化ではなく人間参加型です。必ず専門家による厳密な検証・批判的評価が不可欠であり、人間の科学的思考を補完・加速することを重視しています。実際の成果として、急性骨髄性白血病に対する新規リパーパシング(既存薬再開発)候補の発見および臨床的に適用可能な濃度でin vitroでの腫瘍抑制効果の実証、肝線維症の新規治療標的の発見が報告されています。
AI Scientist-v2(Sakana AI)
日本のSakana AI株式会社が開発したAI Scientist-v2は、人間の研究者の介入なしに、「アイデア創出、実験の設計と実行、データ分析と可視化、論文執筆、自動査読」という研究プロセス全体を自律的に実行するエージェント型AIシステムです[5]。主に計算機科学分野に適用されています。
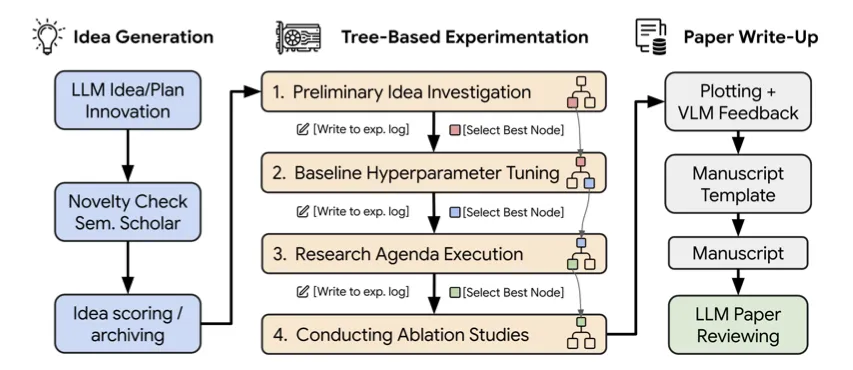
AI Scientist-v2の概要[5]
2024年にv1、2025年にv2が発表され、v1からv2へのアップグレードでより自律的になりました。v2が完全自律で生成した3本の論文を、世界的な機械学習会議ICLRの査読付きワークショップに投稿しました。そのうち1本は、平均査読者スコア6.33(投稿全体の上位約45%)という評価を獲得し、AIが生成した論文が査読プロセスを通過した初の事例となりました。
Robin(FutureHouse)
サンフランシスコの非営利研究機関FutureHouseが2025年に開発したRobinは、様々な科学分野で適用可能ですが、発表論文では創薬で適用されています[6]。疾患に対する仮説の立案から文献調査、実験設計、データ解析、仮説の再構築に至るまで、科学研究の主要な知的工程をすべて担うマルチエージェント型システムです。
3つの専門エージェントを統合しています:
- Crow:実験戦略や治療候補を特定するために簡潔な文献レビューを実施する文献検索エージェント
- Falcon:あらゆる治療候補を評価するために詳細な文献レビューを行い、包括的な報告書を作成する文献検索エージェント
- Finch:実験データを自律的に解析し、新たな仮説生成のための洞察を導き出すデータ解析エージェント
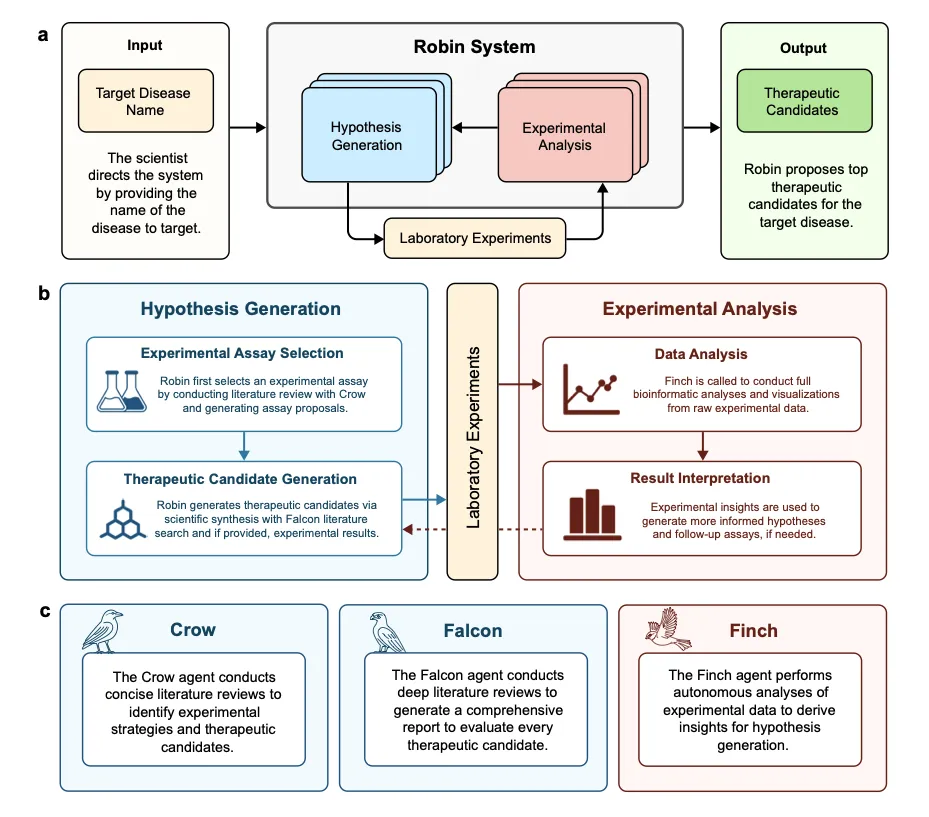
Robinの概要[6]
研究者が疾患名を入力すると、RobinはCrowに問い合わせて疾患に関連する生物学的メカニズムを文献から抽出します。続いて、疾患メカニズムのin vitroモデルと治療薬候補をリストアップし、Falconに問い合わせて各候補の評価を行います。適切な実験手法を設計し、仮説を立案します。実験は人間が行い、得られたデータをもとにFinchが解析を実行し、新たな仮説を提案するというサイクルを繰り返します。
実際の成果として、加齢黄斑変性症に対する新規薬候補の発見が報告されています。
Biomni(Stanford University)
スタンフォード大学が他研究機関や民間企業と共同開発したBiomniは、2025年に発表された汎用バイオメディカルAIエージェントです[7]。幅広い研究タスクを自律的に実行するように設計されています。
2つの主要コンポーネントで構成されます:
- Biomni-E1:統合されたアクションスペースを備えた基礎的なバイオメディカル環境で、150の専門バイオメディカルツール、105のソフトウェア、59のデータベースを含む
- Biomni-A1:Biomni-E1の環境を効果的に活用するように設計された知的エージェントで、研究者が画面上でやり取りする相手。研究者がクエリを入力すると、検索システムにより最も関連性の高いツール、ソフトウェア、データベースを特定します。次に、LLMベースの推論とドメインの専門知識を適用して、詳細なステップバイステップの計画(実行可能コードで表現)を生成します。これにより、複雑なバイオメディカル研究タスクを自律的に実行できるようになっています。
実際の研究におけるパフォーマンスとして、ウェアラブルセンサーデータを解析し生理学的仮説を生成したこと、大規模なオミクスデータを自律的に解析し骨格系統の転写制御に関する洞察を提示したこと、クローニングの実験プロトコルを設計したことが報告されています。
Biomniの詳しい解説記事はこちら:Biomni:スタンフォード発・汎用バイオメディカルAIエージェントの実力と可能性
4. 科学基盤モデル ― タンパク質・ゲノムを理解するAIの進化
基盤モデルとは、大量のデータを用いて事前学習され、さまざまな用途に転用可能な汎用AIモデルを指します。ChatGPTはOpenAIが提供する対話サービスであり、その基盤にはGPTなどの大規模言語モデル(LLM)が用いられています。これらの言語基盤モデルは大量のテキストを学習しており、翻訳、要約、質疑応答、文章生成、推論、コード生成など幅広いタスクに適用できます。
科学基盤モデルは、科学データ(タンパク質・ゲノム・化学構造・実験データ・シミュレーションなど)を大規模に事前学習し、構造予測・仮説生成・解析・シミュレーションなど、科学に関わる多様なタスクに汎用的に使えるAIモデルです。近年登場し、発展を続けています。
ESM3(タンパク質言語モデル)
ESM3は、タンパク質の配列、構造、機能を推論するマルチモーダル生成言語モデルです[8]。
元Meta AI社の研究者らが設立したEvolutionaryScale社が2024年に開発しました。タンパク質の構造予測・機能推定・変異解析に加え、新しいタンパク質のデザインも可能です。esmGFPと呼ばれる新しい蛍光タンパク質の設計に成功しています。
詳細は関連記事「Language Modeling for Biological Sequencesとは?タンパク質の理解と設計を変えるAI技術の最前線」で紹介しています。
Evo2(ゲノム言語モデル)
Arc Instituteが中心となり2025年に開発したEvo2は、DNA、RNA、タンパク質を網羅する汎用的な予測と設計タスクを実行できるゲノム言語モデルです[9]。
多様な真核生物および原核生物ゲノムの9.3兆ヌクレオチド以上を対象に、400億のパラメータと1メガベースのコンテキスト長で学習されています。
Evo2は、ヒト遺伝子における疾患を引き起こす変異を正確に特定できます。例えば、乳がん関連遺伝子BRCA1の変異について、90%以上の精度で良性変異と病原性変異を予測できます。また、単純な細菌ゲノムと同程度の長さの新たなゲノムを設計することが可能です。
仕組みは、進化がDNAとRNAに刻んだ生物学的情報のパターンを学習することにあります。インターネット上の言語を学習した大規模言語モデルと同様に、進化は生物学的配列にその痕跡を残しています。数百万年にわたって洗練されたこれらのパターンには、分子の働き方や相互作用に関する信号が含まれています。Evo2は、128,000以上の全ゲノムから9.3兆以上のヌクレオチドを学習し、生命の全領域にわたる一般的な理解を獲得しています。
特徴として、タスク固有のファインチューニングなしで予測が可能な「ゼロショット予測」能力が挙げられます。DNA、RNA、タンパク質という3つのモダリティ(セントラルドグマの3要素)と3つのドメイン(原核生物、古細菌、真核生物)を横断的に学習しているため、配列の確率を計算するだけで、変異の影響や機能を予測できます。
AlphaGenome(変異影響予測モデル)
Google DeepMind社が2025年に開発したAlphaGenomeは、ヒトDNA配列における単一のバリアントまたは変異が、遺伝子制御にどう影響するか予測するモデルです[10]。ヒトおよびマウスのゲノムから多様な分子表現型の配列基盤を学習しています。
最大100万塩基対の長いDNA配列を入力として受け取り、その調節活性を特徴付ける数千の分子特性を予測します。変異配列の予測値と変異していない配列の予測値を比較することで、遺伝子変異の影響をスコアリングします。
AlphaGenomeの特徴として、高解像度での長いシーケンスコンテキストが挙げられます。最大100万塩基対を解析し、個々の文字の解像度で予測を行います。従来のモデルでは、配列の長さと解像度をトレードオフする必要がありましたが、AlphaGenomeはこの制約を克服しました。
また、新しいスプライスジャンクションモデリング機能も重要です。多くの希少遺伝性疾患はRNAスプライシング(RNA分子の一部が除去されて残りの末端が再結合する)のエラーで起こります。AlphaGenomeは、スプライシング部位と発現レベルを配列から直接モデル化できる初のモデルで、遺伝子変異がスプライシングに及ぼす影響をより正確に捉えられます。
5. まとめとこれから
AI for Scienceは、科学研究のあり方を変革しつつあります。分野によって変化の速度や規模に違いはあるものの、近い将来、研究の手法やプロセスは変化していくでしょう。
特に機械学習分野はAIとの親和性が高く、Sakana AIのAI Scientistのような調査・仮説生成から論文執筆までを自律的に実行するAIエージェントが現れています。 一方、ライフサイエンス分野は物理空間での実験を必要としており、AIが研究活動の全てを担うには技術面・運用面の制約が存在します。実験操作を自動化するラボラトリーオートメーションも注目されていますが、装置の整備や実験手順の標準化には相応の準備と投資が求められます。そのため、AIが汎用的に実験室を操作し研究を自律的に進める段階には、まだ時間を要すると考えられます。
そのため当面は、AIが研究者を完全に置き換えるのではなく、人間研究者と役割分担しながら協働する形が現実的な方向性となります。AIは文献調査やデータ解析、仮説生成といった知的作業を担い、人間は実験設計や結果の解釈、意思決定を担うことで、研究全体のスピードと質を高めることが期待されます。こうした協働の積み重ねは、将来的にAIがより広い研究プロセスを担う可能性を検討していく上での、重要な基盤になると考えられます。
参考文献
[1] 文部科学省, 「第44回情報委員会 議事録・配付資料」, 2025年, Accessed: 2025-10-31., https://www.mext.go.jp/b_menu/shingi/gijyutu/gijyutu29/siryo/1418998_20250424_00002.html
[2] 文部科学省, 「【資料1-5】AI for Scienceの推進に向けた基本的な考え方について」, 2025年, Accessed: 2025-12-17., https://www.mext.go.jp/content/20251006-mxt_jyohoka01-000045188_04.pdf
[3] 文部科学省, 「【資料1-2】AI for Science / 概念と方向性」, 2025年, Accessed: 2025-12-17., https://www.mext.go.jp/content/20251006-mxt_jyohoka01-000045188_01.pdf
[4] Gottweis et al., “Towards an AI co-scientist”, arXiv(2025), https://doi.org/10.48550/arXiv.2502.18864
[5] Yamada et al., “The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search”, arXiv(2025), https://doi.org/10.48550/arXiv.2504.08066
[6] Ghareeb et al., “Robin: A multi-agent system for automating scientific discovery”, arXiv(2025), https://doi.org/10.48550/arXiv.2505.13400
[7] Huang et al., “Biomni: A General-Purpose Biomedical AI Agent”, bioRxiv(2025), https://doi.org/10.1101/2025.05.30.656746
[8] Meier et al., “Simulating 500 million years of evolution with a language model”, Science 387(2025): 850-858., https://www.science.org/doi/10.1126/science.ads0018
[9] Brixi et al., “Genome modeling and design across all domains of life with Evo 2”, bioRxiv(2025), https://doi.org/10.1101/2025.02.18.638918
[10] Avsec et al., “AlphaGenome: advancing regulatory variant effect prediction with a unified DNA sequence model”, bioRxiv(2025), https://doi.org/10.1101/2025.06.25.661532
最新情報をお届けします
AIと科学研究に関する最新記事、イベント情報、AI for Scienceのヒントをメールでお届けします。いつでも配信解除可能です。
Contact
Science Aidは、研究を中心とした幅広い領域をAIによって支援します。システム開発やコンサルティング、共同研究、セミナーのご依頼などお気軽にご相談ください