BixBench:Bioinformaticsタスクに対するAIエージェントのベンチマーク
FutureHouse(AI科学者作成を目指す非営利団体)とScienceMachine(サンフランシスコを拠点とするAI駆動のバイオメディカル研究技術スタートアップ)が共同で発表したBixBench(Bioinformatics Benchmarkの略)は、LLMベースのエージェントがバイオインフォマティクスのデータ解析をどこまでできるかを評価するベンチマークです。2025年2月に最初のarXiv論文が公開され、その後2度更新されて2025年10月が最終版となっています(doi:10.48550/arXiv.2503.00096)。
この記事では、BixBenchの概要を紹介します。
基本構成
BixBenchは、専門家によって作成・レビューされた質の高い評価データで構成されています:
- 61個のカプセル:すべて専門家が作成した、現実世界の生物学的データ解析シナリオ
- 205個の質問:質問と回答の選択肢はClaude 3.5 Sonnetを使用して草案が作られ、すべて人間の専門家によってチェック・編集・承認(または却下)が行われた
エージェントに与えられる環境
カプセル(Docker環境内)には、解析すべきデータと、解析可能な環境が用意されています。 エージェントは、以下の3つのツールだけを使ってカプセル環境にてデータ解析を行います:
list_workdir:どんなファイルがあるか確認edit_cell:プログラミングコードを書いて実行submit_answer:最終的な答えを提出
例えば、あるカプセルに対してエージェントが評価データの指示に従いデータ解析を行う場合:
Step 1: list_workdir() → ファイル一覧を確認
Step 2: edit_cell() → データ読み込みコード実行
Step 3: edit_cell() → 統計解析コード実行
Step 4: edit_cell() → 可視化コード実行
...このような一連の行動をトラジェクトリと呼ばれています。エージェントは、このトラジェクトリを通じて得られた解析結果に基づき、カプセルに関連する複数の質問(例:「どの遺伝子が最も発現変動が大きいか?」「p値はいくつか?」など)に対して submit_answer() で答えを提出していきます。
評価方法
BixBenchでは、2段階でエージェントの回答が生成されます:
第1段階:Open-Answer形式での回答生成
- エージェントが
submit_answer()で提出した自由回答
第2段階:MCQ (Multiple-choice questions) 形式での選択肢選択
- 第1段階で生成した回答とトラジェクトリを通じて得られたデータ解析過程を使い、選択肢から回答を選択
この2パターンの回答生成に基づき、以下の3つの評価方式が提供されます:
- Open-Answer形式:第1段階で提出された自由回答のみを評価
- MCQ w/o refusal(Refusalオプションなし):第2段階にて通常の4択選択肢から選択された回答を評価
- MCQ w/ refusal(Refusalオプションあり):第2段階にて「情報不十分で回答できません」という選択肢を追加した5択から選択された回答を評価
Open-Answer形式(第1段階)
Open-Answer形式では、エージェントがデータ解析に基づき自由回答し、その回答のみが評価対象となります。エージェントの回答が正解と完全一致しなくても、意味的に同等であれば正解とみなされます(例:「BRCA1遺伝子」と「BRCA1」)。
論文発表当時(2025年上旬)のフロンティアモデルでは、この形式での正解率は約21%と非常に低く、最終出力のみでは高いスコアを出すことが難しいため、難易度を下げた評価手段としてMCQ形式が導入されました。
MCQ形式(第2段階・2種類)
MCQ形式では、第1段階で生成したOpen-Answer回答とデータ解析の過程、そして選択肢をLLMに入力し、最も適切な選択肢を1つ選ばせます。第1段階の情報を活用することで、選択式でありながらエージェントが解析過程の情報も含めて適切に回答を選択できるかを測定できます。
MCQ形式には2種類があります。MCQ w/o refusalは通常の4択問題、MCQ w/ refusalは「情報不十分で回答できません」という選択肢を追加した5択問題です。
Refusalオプションが用意された理由
BixBenchのタスクは本来、適切にデータ解析を行えば必ず答えが得られる設計になっています。にもかかわらず「情報不十分で回答できません」という選択肢(Refusal)が用意されている理由は以下の2つです:
- 「事前知識への依存」を浮き彫りにする:LLMは解析に失敗しても、事前学習で獲得した知識に基づいて「それらしい答え」を生成してしまう傾向がある。Refusal選択肢があることで、モデルが適切な解析結果を得られていない時に、事前知識に頼って無理やり答えを出していないかを測定できる
- モデルの「誠実さ(Ethics)」を評価する:バイオインフォマティクスでは、確証がないのに適当な数値を報告することは科学的に危険。「分からないときは分からないと言う」能力も重要
結果と考察
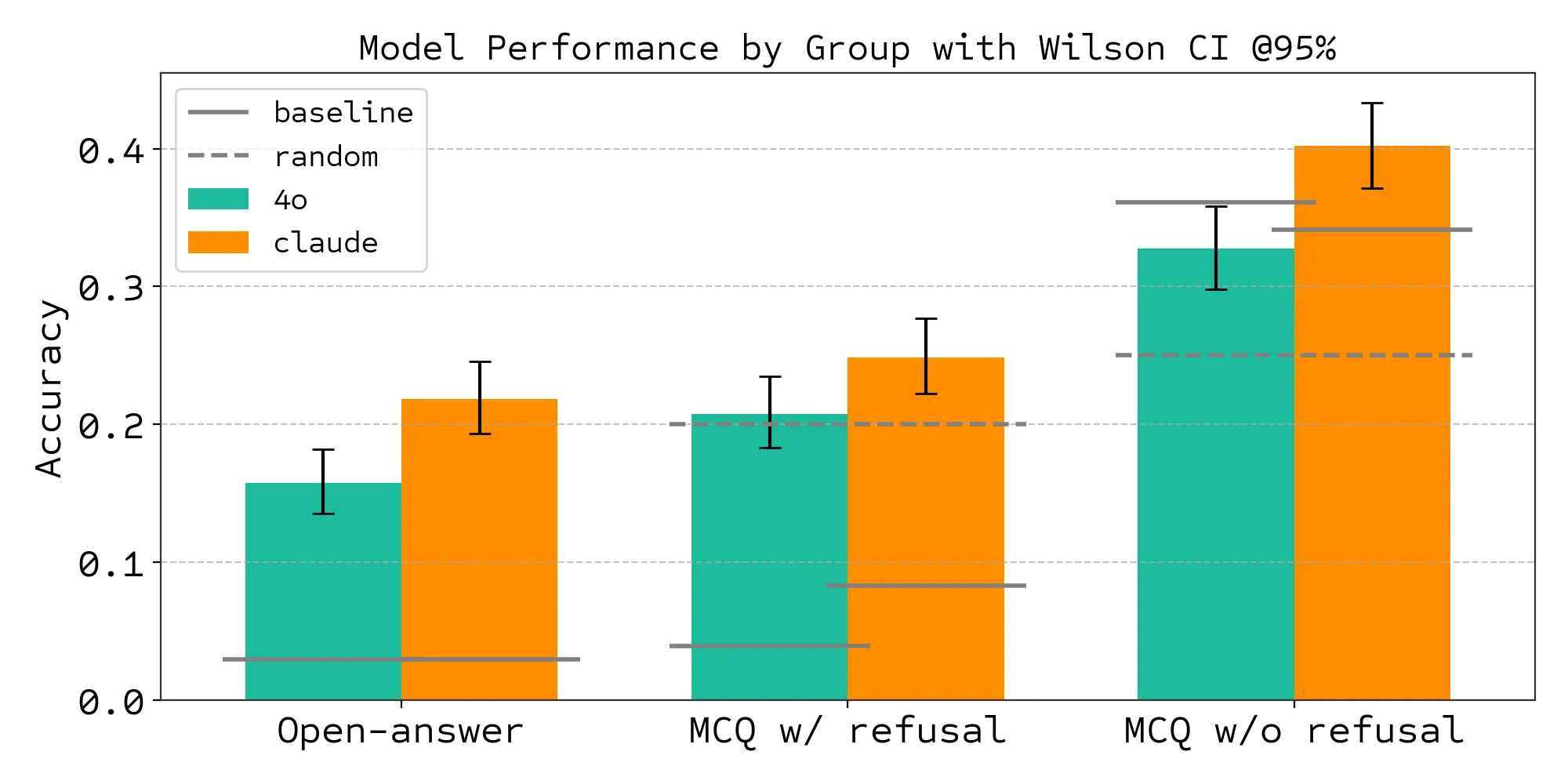
図: GPT-4oとClaude 3.5 Sonnetにおける評価形式別の正解率比較(論文より)
図中の緑とオレンジのバープロットは、データ解析とその解析結果も含めたBixBenchシステムでの評価結果を示しています。 図中の灰色実線:baselineは、データ解析結果を一切与えずに質問だけ与えて答えさせた際の正解率を示し、灰色点線は選択問題をランダムに解かせる場合の確率(4択の場合は0.2、5択の場合は0.25)を示しています。
各評価形式でのbaselineの違い:
-
Open-Answer:選択肢がないため、baselineの正解率は低い。
-
MCQ w/ refusal:選択肢は与えているが、Refusalオプション(情報不十分なので回答できないという選択肢)があると、引き続きbaselineが低いままとなる。
-
MCQ w/o refusal:一気にbaselineが上がり、ランダムである0.25を超える正解率となる。これはLLMが想起(事前知識)に基づいて無理やり近い選択肢を選ぶ傾向があることを示唆。
baselineを踏まえた評価結果の考察:
baselineの結果を踏まえ、今回のGPT-4o、Claude 3.5 Sonnetでの評価結果を見ると、以下の傾向が観察されます:
-
Open-Answer:baselineより大幅に正解率が向上。データ解析が正解率向上に寄与したことが確認できる。
-
MCQ w/ refusal: Open-Answer形式と比較して、正解率が微量向上している。しかしその正解率は選択肢をランダムに選んだ場合(0.2)とそこまで変わらない。さらにMCQ w/o refusalと比較すると大幅に正解率は下がっている。Refusalオプションがあることで、エージェントが自信がない場合に回答を辞退する傾向を持っていることが示唆されている。
-
MCQ w/o refusal: Open-Answer形式と比較して、正解率が向上している。選択肢をランダムに選ぶ確率(0.25)より正解率は高いものの、baseline自体も近い正解率を示している。つまり、データ解析を行っても行わなくても大差がないため、LLMのバイオインフォマティクス能力の性能とは言い難い可能性が高い。論文著者らは、これは主にモデルが解析結果ではなく事前知識に依存して回答しているためと推測している。
GPT-4oやClaude 3.5 Sonnetといった当時のモデルは、「厳密な解析結果」よりも「もっともらしい事前知識」を優先してしまうという、自律的なバイオインフォマティクス研究における根本的な課題がある、と考察されています。
AIが苦戦する3つの理由
論文では、AIエージェントがBixBenchで苦戦する理由として、以下の3つを挙げています。
1. 多段階の計算が必要
バイオインフォマティクスのデータ解析は、複数の工程から構成されることが多く、どれか1個のステップでもエラーが起きると、全体が失敗します。
たとえば、遺伝子発現変動解析の例:
質問例: 「二群間で発現が有意に異なる遺伝子は何か?」
必要なステップ例:
1. データの読み込みと品質管理
2. 前処理とフィルタリング
3. 正規化
4. 統計モデルの適用
5. 変動遺伝子の選別と生物学的解釈
→ どこかのステップでもエラーが起きると、全体が失敗このような多段階推論が必要なタスクにおいて、エージェントは各ステップで適切な判断を下す必要があり、それが困難さの主要因となっています。
2. 多様な形式と型、不均質なデータの処理
バイオインフォマティクスのデータは、多様な形式と型を持ち、不均質です:
- 異なるファイル形式(CSV、RDSなど)
- 異なるデータ型(数値、カテゴリカル、テキストなど)
- 欠損値の扱いの違い
- データ構造の複雑さ(階層的、ネストされたデータなど)
エージェントは、これらの多様で不均質なデータを適切に扱う必要があります。各データ形式や型に応じた適切な読み込み方法や処理方法を理解し、データの不均質性に対応する能力が求められます。
3. プロット(図表)の解釈
論文では、プロット(図や表)の解釈が困難であることが指摘されています。データ解析の過程で生成された図表から適切な情報を読み取り、次のステップに活用する能力が求められますが、論文発表当時のマルチモーダルモデルでは科学的な図表の理解が不十分でした。
まとめ
BixBenchの調査を通じて、以下のことがわかりました:
ベンチマークの特徴
- 質の高い評価データ: すべて専門家によって作成・レビューされた61個のカプセルと205個の質問
- 現実的な難易度: GPT-4oやClaude 3.5 Sonnetで正解率20%前後という非常に挑戦的なベンチマーク
AIエージェントの課題(GPT-4o・Claude 3.5 Sonnetを用いた場合)
- 多段階推論の困難さ: 複数のステップから構成される解析で、どこか1つでもエラーが起きると全体が失敗
- 多様で不均質なデータの扱い: 異なる形式・型・構造を持つデータへの対応が不十分
- 図表解釈の限界: マルチモーダルモデルによる科学的な図表の理解が不足
- 事前知識への依存: データ解析を行っても行わなくてもMCQ w/o refusalの正解率がほぼ同等(データ解析結果とbaseline結果が近い)であり、解析結果よりもモデルの事前知識に基づいて選択肢を選んでいる可能性が高い。「厳密な解析結果」よりも「もっともらしい事前知識」を優先してしまうという、当時のモデルにおける根本的な課題が浮き彫りになった
今後の展望
BixBenchの評価データとその評価コンセプトは、バイオインフォマティクス分野におけるAI for Scienceの進展を測る上で有用であり、今後のモデルやエージェント技術の発展を評価する上で重要なツールになると考えています。
参考リンク
- 論文: BixBench: A Comprehensive Benchmark for LLM-based Agents in Computational Biology
- GitHub: https://github.com/Future-House/BixBench
- Hugging Face: futurehouse/BixBench
- ブログ: FutureHouse Research Announcements
最新情報をお届けします
AIと科学研究に関する最新記事、イベント情報、AI for Scienceのヒントをメールでお届けします。いつでも配信解除可能です。
Contact
Science Aidは、研究を中心とした幅広い領域をAIによって支援します。システム開発やコンサルティング、共同研究、セミナーのご依頼などお気軽にご相談ください